Data upload¶
Check for protocol¶
Warning: Before uploading a dataset you have to be sure that the related protocol is already in the portal. If it’s not yet available, follow the instruction for protocol upload
Create a dataset¶
Login with a user with editor role for the module the dataset belongs to
Go to Datasets and select “Add Dataset” (if not visible, you are not authorized: contact the module leader)
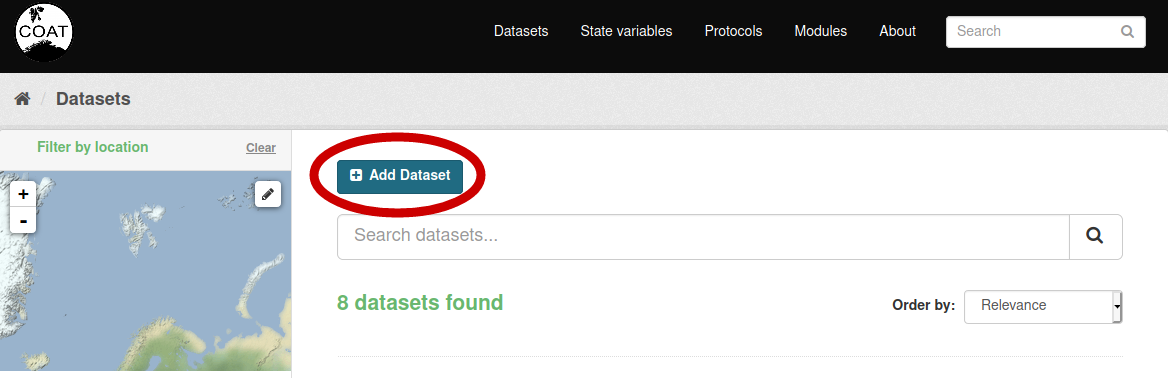
Edit metadata¶
The first operation required to add a new dataset to the portal is editing the metadata:
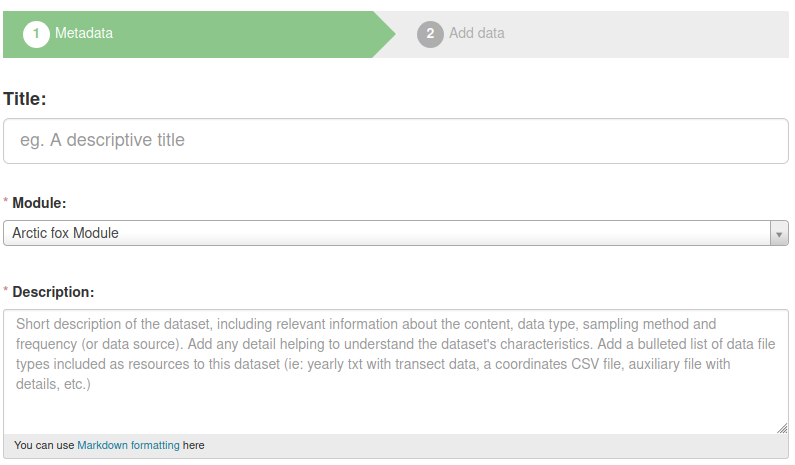
Title (mandatory): should be identical to the dataset name (formatted according the formatting rules). It should start with a conventional prefix (starting with V_ for datasets from Varanger and S_ for datasets from Svalbard)
Module (mandatory): Select the module related to the dataset. The user need to be editor for the module.
Description (mandatory): Add a short description of the dataset. Here an example in Markdown format:

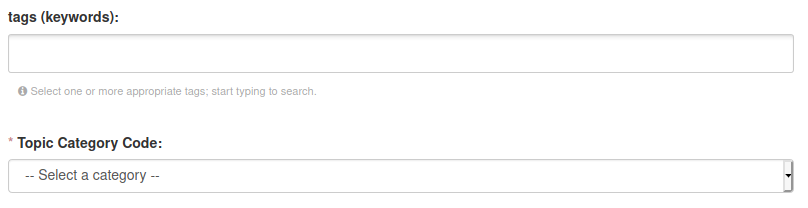
Tags: Choose a list of keywords from a controlled vocabulary
Topic Category Code: This is a general category for classifying data, following a commonly used standard in data repositories
Embargo: Select an embargo policy. If the dataset doesn’t require an embargo, go on with next point. If your dataset include data less than 2 years old, you could select an embargo end date. Read the detailed instructions on how to manage embargo data and dataset versions here

License: Defines which License is given to data. Defaults to CC-BY 4.0, chosen as the COAT project’s license for data.

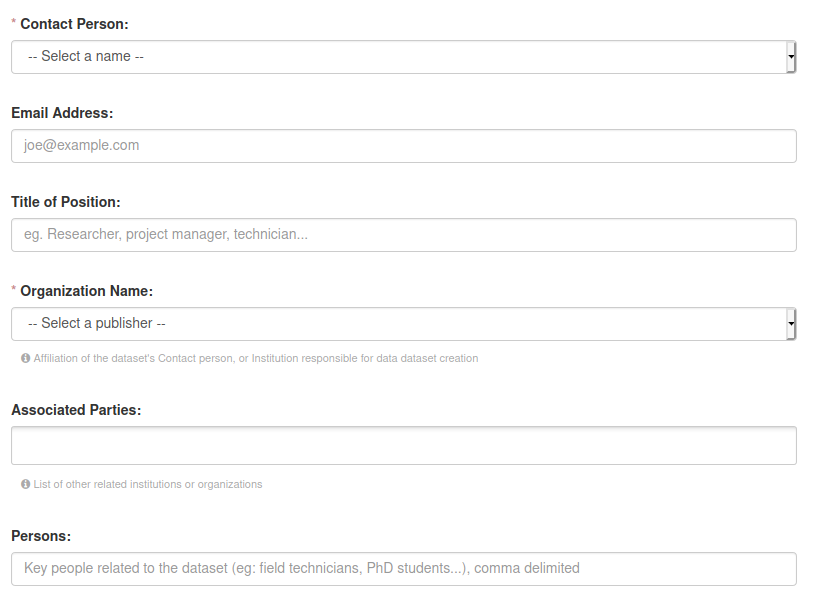
Contact Person (mandatory): It is the name of the person responsible for the dataset. Could be different from the person editing metadata. choosen from the list of registered users.
Email Address: of the contact person.
Title of Position: What is the professional role of the contact person?
Organization Name (mandatory): Which of the COAT partner Institutions is responsible for the dataset?
Associated Parties: Additional institutions that are involved, either COAT partners or external institutions:
UiT - The Arctic University of Norway
NPI - Norwegian Polar Institute
NINA - Norwegian Institute for Nature Research
MET - Norwegian Meteorological institute
UNIS - University Centre on Svalbard
AU - University of Aarhus
Persons: Are there other key people related to the dataset? Ex: Field Technicians, PhD students, people who were in charge of the dataset previously etc.
Temporal Extent: What is the time span of the included data?

Geographic Location: choose one or more locations related to the dataset collection. The taxonomy is hierarchical, so you only need to choose the most detailed location names (all upper locations will be added automatically). The location names are used to create a bounding box, used also for geographical filtering of the datasets on the minimap.

Scientific Name: One or more choices allowed. Scientific names of the species described by the datasets

Associated Scripts: A link to the repository with publicly available scripts related to the dataset. Typically scripts that use the COAT raw data for calculating state variables.

Associated Study Protocol (mandatory): This is the study protocol describing the dataset, choosen from he available ones. A study protocol needs to be added in its specific section before adding a dataset.

Bibliographic Citation: TODO
Funding Source: Describe the source of funding, if relevant.

After filling all metadata, select Next: “Add data”

Upload all the data files in the order described below, add a filename (best to keep the file’s name by click on “Fill field with filename or URL”) and choose the correct file format
Data files upload order¶
Upload the readme file as a PDF/A. A description can be added, for example: “Additional information about the dataset, including a description of the variables included in the dataset”
Upload the auxiliary file/s A description can be added, for example: “Auxiliary information about the sampling sites including information about whem the site has been included in the sampling design”
Upload the coordinates file. A description can be added, for example: “Coordinates of all sites included in the dataset”
Upload all data files in chronological order (from older to newer)
Note: It is also possible to change the file order in a second moment
Data upload alternatives¶
Data files can be uploaded one by one using the data portal graphic interface, as described above. However, in case of the upload of many data files, it could be convenient to use the data portal’s API and data upload scripts.
Please refer to the github repository containing data management scripts:
Private or public datasets¶
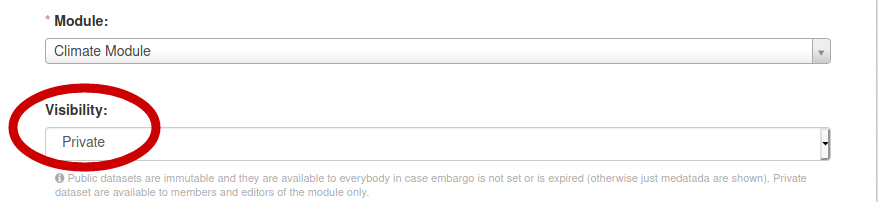
When a dataset is created, it defaults to “private” status. A private dataset is not visible or accessible by unregistered or regular users. Only logged-in users who are members or editors of the module including the dataset can see it
Publishing the dataset¶
After the upload is completed, the dataset can be set to ‘Public’ by selecting ‘Manage’ in the menu of the dataset and setting the ‘Visibility’ metadata element to ‘Public’.

Dataset Versions¶
Datasets already published cannot be removed or modified, because of the FAIR requirement of being permanent and findable for citation and reuse purposes. whenever a dataset content changes, it is necessary to create a new version of it.
Whenever a dataset gets created, the system automatically adds a version prefix: At the first dataset creation the dataset will have “_v1” added at the end of the name. When the dataset has been published, it is possible to modify it’s content only by creating a new version. To create a new version, click on the “New Version” button:

This will create a new version, which will be visible on the left bar, with buttons to switch from version to version:
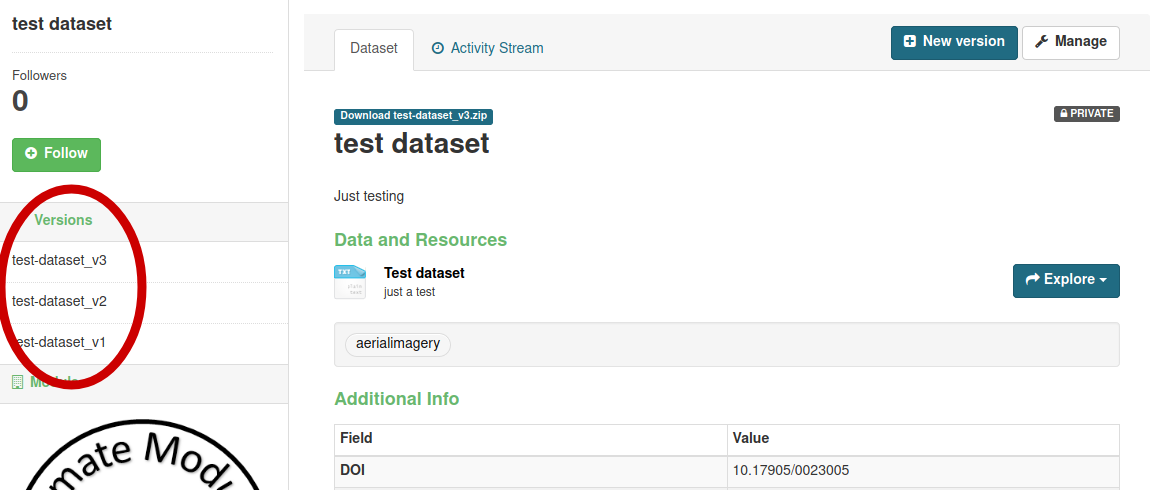
Every version of a dataset has it’s own identity and DOI, which allows accurate dataset citation in publications at the version level. Whenever visualizing an older version of a dataset, a friendly reminder will inform the user that it is an older version, with a link to the latest.
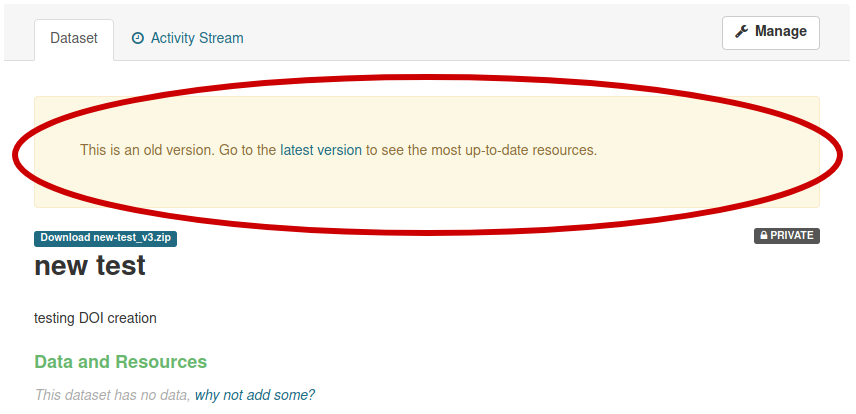
When accessing to a dataset’s main page, it will always show the latest public version of the dataset
Updating a dataset¶
After creating a new version of a dataset, which is identical to the previous version at the moment of creation, a user should modify the dataset to add data files or modify metadata.
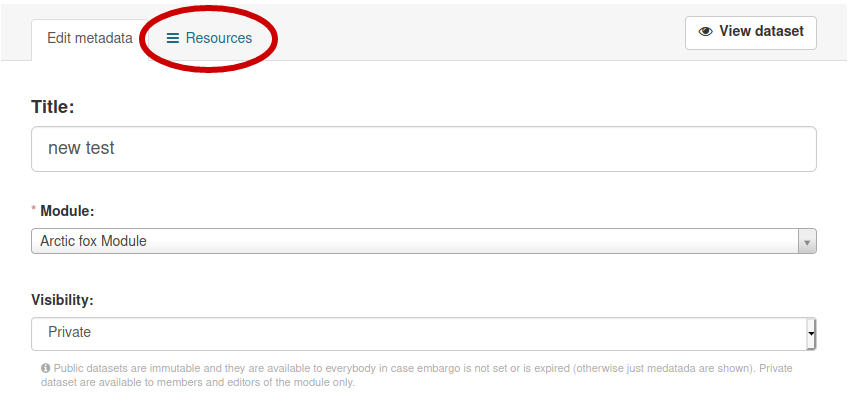
For both operations a user needs to click on the “Manage” button (top right) of the dataset page:
The “manage” button will bring the user to the editing section for a dataset, defaulting to metadata editing. If a user needs to upload new data files instead, it is enough to click on the “Resources” TAB, then “Add new resource”:
Upload a State Variable¶
state Variables are a special type of secundary dataset, which are calculated from primary data originating either from within COAT or from external sources. The State Variables are the primary input to the quantitative analysis and predictive modelling performed in COAT.

State Variable management is similar to the dataset management, with the exception of having less metadata elements and one specific metadata element added. In fact, State Variables are derived from input datasets listed under the “Datasets” TAB, and contain provenance information in their metadata. Specifically, while adding a new State Variable, a user selects a list of associated data picked from the input datasets available in the portal:
It is possible to pick specific versions of the datasets, and information about the time span covered by the dataset’s version will be visible.
Embargo management¶
Datasets with an embargo follow a particular setup, which guarantees availability of older data contents and protection of more recent ones.
By default COAT data follow an Open Data policy. It is however possibile to create datasets with a two-year embargo. This would typically be the case for a dataset where older data is set publicly available but the last two years data is only available for COAT users. In such case, only users with user or editor status in the relevant module can see the data.
Warning: the embargo management is a bit complex, please read carefully the details below:
When a dataset contains data files which should be kept in embargo (not reachable), there is a specific workflow to follow, which implies the use of dataset versions. It requires to create more than one version of a dataset, with the first version without an embargo, with data files reachable, and one or two versions in embargo, without data access. Such a workflow allows visualizing the most updated metadata, and the list of files, but keeps accessible only data from the non-embargoed dataset.
A user selects the embargo end date for the versions with embargo data files. A dataset version in embargo will keep all the data files inaccessible until the embargo end date, then will automatically make them available at the embargo end date. Non-authorized users will be informed that a dataset is under embargo, and need to look for a previous version (the one with non-embargoed data files)
Let’s see an example…
Ola Nordmann is a data portal’s editor. On January 1st 2021 he decides to upload a new dataset containing one data file per year (from 2000 to 2020). He opts for keeping the latest 2 years of data in embargo (the only eligible for such exception). Please consider that keeping all the data public is the best choice, whenever possible, and often a mandatory requirement from public research funders.
Here his workflow:
Ola creates the first dataset version, which contains only data which can be public (from year 2000 to year 2018), and calls it “sample_dataset”.
This dataset will be automatically labelled as “sample_dataset_v1”.
Ola publishes “sample_dataset_v1”.
Ola creates a new version using the “New Version” button, which will create automatically “sample_dataset_v2”.
Ola adds 1 data file containing data for the year 2019, so that “sample_dataset_v2” contains data from 2000 to 2019.
Ola sets the embargo end date on January 1st 2022, and publishes “sample_dataset_v2”.
Ola creates a third version of the dataset, “sample_dataset_v3” including year 2020, with embargo end date January 1st 2023.
Ola publishes also “sample_dataset_v3”
Ola may use python or R (ckanr) scripts using his api key credentials to download even the embargo files whenever needed.
After 1 year, “sample_dataset_v2” removes all the blocks to data access, letting available also data from year 2019, and becomes the default version of the dataset (the latest published version).
Ola now has one more year of data, 2021, and creates a new version, including 2000 - 2021 (embargoed) with embargo end date january 1st 2023.
And so on…